침플레닛 회고록
react
작성일 : 2023.08.25
팀프로젝트 회고록
최근 침플래닛 이라는 팀프로젝트가 성공적으로 마무리 되어 처음으로 회고록을 작성해 보려 한다. 이번 프로젝트를 진행하면서 개인적으로 많은 성장을 이뤄냈다고 생각해 정리해보도록 하겠다.
프로젝트 진행과정
내가 프로젝트에 합류 했던 당시 이미 모든 팀원이 구해져 있던 상황이였다 기획 : 1명 백엔드 : 3명 프론트 : 2명 기획 : 1명 일러스트 : 1명 웹 디자이너 : 1명 그래픽 디자이너 : 1명 으로 이루어졌다. 합류한후에 인수인계 겸 회의를 진행 했는데 내 걱정과는 다르게 자유롭고 재미있는 분위기에서 진행되는 회의였다. 다들 아이디어를 말하는데 거리낌 없었고 아이디어가 나오면 기능적으로 무엇이 필요하고 어떤 점이 추가되야 하는지에 대해 이야기했다. 두어번의 기획 회의를 마치고 프로젝트 개발에 들어갔다. 백엔드는 크롤링한 데이터를 어떻게 하면 효율적으로 뷴류하고 저장하는지에 대해 프론트는 웹 디자인이 나오는 대로 빠르게 일정에 맞춰 기능들을 구현하는지에 대해 초점을 맞춰 프로젝트를 진행해 나갔다. 매주 주말마다 모여 서로 있었던 이슈와 진행상황을 보고하는 시간을 가졌고 우선 MVP를 우선으로 배포한 후 추후 유저 반응을 살펴 기능들을 추가하기로 했다.
서비스 아키텍쳐
프로젝트의 전체적인 틀은 네이버 팬카페 왁물원의 인력사무소 게시글들을 스크랩해 분류해주는 기능을 제공하고 제대로 분류되지 않은 게시글들은 관리자 페이지에서 추가로 수정해주기로 했다.
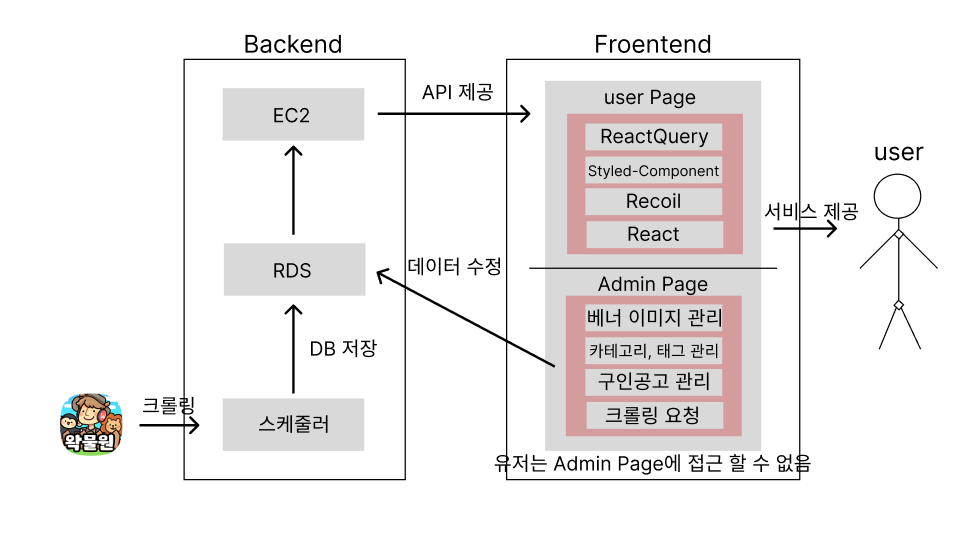
내가 담당한 부분
무한 스크롤
분류한 게시들을 보여줄 때 페이지 네이션 VS 무한 스크롤 VS 더보기 버튼 을 고민하다가 모바일 환경 지원을 생각해 무한 스크롤으로 구현하기로 했다. 무한 스크롤을 구현 할 수 있는 여러가지 방법이 있는데 나는 Intersection Observer API 을 선택했다. 그 이유는 스크롤 이벤트를 사용했을 때 이벤트가 실행 될 때 마다 함수가 호출되면 브라우저 성능에 비 효율적이라는 판단이 들었고 다양한 모바일 유저들의 디바이스 성능들을 생각해서 성능저하가 유발될 만한 것을은 빼기로 했다. 그에 비해 Intersection Observer API는 요소가 뷰 포트에 포함이 되는지를 관찰하는데 비동기적으로 실행되며 렌더링 성능이나 이벤트 연속 호출 문제가 나타나지 않다는 장점이 있다. 그러나 생각 한 것 처럼 기능을 구현하는건 쉽지 않았다. 요소를 관측 했을 때 다음 데이터를 가져와야 하는데 자꾸 중복된 데이터가 호출되는 문제가 있었다. 이 부분을 호출한 데이터의 마지막 게시글 Article_Id를 파라미터로 보내줘 다음 데이터를 보내주도록 했다.
어드민 페이지
크롤링한 데이터를 분류할 때 잘 못 분류된 경우 수정을 해주어야 하는데 그 때 마다 코드를 수정해 배포를 할 수 는 없어서 어드민 페이지를 만들기로 했다.
침플래닛 서비스에서는 다음과 같이 게시글을 분류해준다 구인 마감 여부와 게시글들을 태그 분류해 원하는 분야의 구인글들만 볼 수 있다. 그러나 구인이 마감 됐으나 구인중이라고 뜬다거나 디자이너를 구인하고 있는데 디자이너 태그가 붙지 않는등 분류가 안된 게시글들이 보이는데 이를 수동으로 분류해주는 것 이다. 처음 이 부분을 담당 했을 때 단순한 CRUD라고 생각해 어렵지 않겠다고 생각을 했지만 생각보다 쉽지 않았다. 이유는 이를 관리해주는건 개발자가 아니라 일반인 관리자였기 때문에 각종 오류와 유지보수가 쉽게 만들어야 했기 때문이다. 예를 들어 구인중 과 구인 마감이 동시에 선택 할 수 없게 하는 것 이였는데 이 부분은 체크 박스를 이용해 하나의 체크 박스를 선택하면 나머지 하나는 체크가 해제되도록 만들었다. 태그를 분류 할 때 최 상단에 카테고리가 있고 그 하위에 각종 디테일한 태그들이 붙는다 예를 들어 개발 이라는 카테고리에 디자이너 라는 태그를 부여할 수 없는 로직을 만드는게 쉽지 않았는데 이 부분은 태그를 추가하면 그 태그를 포함하고 있는 상위 카테고리를 찾아 자동으로 선택 되도록 만들어 오류를 방지할 수 있었다.
왁물원에서 주로 구인하는 직군들을 모아 임의로 카테고리화 해 태그로 분류하는 작업을 가졌다. 하지만 각 분야에 대해 잘 모르다 보니 잘못 분류한 카테고리나 추가하지 못 한 태그에 대한 관리가 필요하다는 의견이 나와 카테고리 추가와 각 카테고리에 태그 추가 및 삭제 기능을 만들었다. 하지만 기능을 다 만들고 나니 카테고리와 태그를 추가하게 되도 서버에서 이를 분류하는 로직이 없으면 껍대기만 있는 기능이라 추가만 해두고 사용하지 않기로 했다.
이슈
프로젝트를 진행하면서 가장 많이 나왔던 이슈는 바로 서버비용이였다. 우리는 AWS를 이용해 백엔드와 프론트 서버를 분류해 각각 올렸는데 서비스를 시작하고나서 트레픽이 몰리면 비용을 어떻게 부담해야 하는지에 대해 큰 고민에 빠졌는데 하지만 얼마 안 가 AWS에 메일을 보내 1000크래딧을 받아와 당장 급한 문제는 해결 할 수 있었다. 서버비용에 대한 문제가 해결되고 나니 두번째로 나온 이슈는 서버가 트래픽을 감당할 수 있는가 였다. 그때 당시만 해도 개발을 하다보면 서버가 갑자기 죽어버리는 이슈가 있었다. 그래서 우리는 이 이슈에 대한 원인을 찾다 서버에서 크롤링을 해와 태그정보별로 분류를 할 때 서버에 일시적으로 부하가 걸려 다운되는게 아닌가 라는 결과에 달했는데 이 부분을 안정화를 진행했다 하지만 로직 최적화를 진행 했음에도 자꾸 다운되는 이슈가 있어 살펴보니 CI/CD가 원인였고 CI/CD를 다시 구축해 문제를 해결할 수 있었다.
어려웠던 점
프로젝트를 진행하면서 가장 애를 먹었던 부분은 팀원이 작성한 코드를 읽고 이해하는 부분이였다. 다른 사람과의 협업을 해본 경험이 없고 Git을 이용한 Workflow 경험이 없는 나는 문제가 발생 했을 때 적지 않게 당황을 했다 하지만 이 부분은 지속적인 코드리뷰와 커뮤니케이션을 통해 해결 할 수 있었다.(이 부분은 4년간의 직장생활이 도움이 됐다) 팀 프로젝트를 진행하면서 느낀점은 지금 까지 클론 코딩을 해오면서 쌓아온 지식들이 전부 모래로 쌓아 올린 성 같다는 느낌이 들었다. 분명히 들어본적 있고 해본적 있지만 막상 말로는 잘 설명 할 수 없는 순간이 많았고 이 때문에 문제를 해결할 때 문제를 정의하기 어려웠다. 이제 부터는 기존에 습득 했던 지식들을 정리하고 응용해보며 탄탄히 기초부터 쌓아 올리기로 했다. 기초를 잘 다져 놓는 다면 문제를 해결함에 있어 더욱 수월하게 문제를 정의 할 수 있을 것 같다.
개선사항
우선 빠른 구현을 위해 JS로 작성했던 코드를 전부 TS로 변경하기로 했다. 이유는 생각보다 유저 반응이 좋았고 계속 유지보수를 위해서 TS로 변경하기로 했다 서버데이터 관리를 위해 react-query를 선택했다 하지만 react-query의 캐싱을 제외한 다른 기능들은 거의 사용하지 않기 때문에 성능 개선을 위해 swr로 변경하기로 했다.